回帰分析「Airbnbのオープンデータから宿泊費を予測」(ちょいみる統計 )
ここ数年でデータドリブンな経営・マーケティングの意思決定が重要性を増す中、経営企画やマーケティング担当者の方の中には、データリテラシーやスキルを磨かれている方も多いかと思います。本ブログはそんな方々のために、統計手法やデータの解釈の仕方を、細かい数式などは一度省いて、ご紹介していければと思います。
また昨今、政府や企業による「オープンデータ」の活用推進により、自社の外部環境を知るために利用できるデータも豊富になってきています。
しかし、、実際に活用されている方でなければ、どの様なデータが公開されているかを知る機会も、なかなか少ないのではないのでしょうか。
そのため、どの様な「オープンデータ」が公開されているかも、同時にご紹介できればと思います。
例えば、政府によるオープンデータ活用プラットフォームの『LinkData』では、市町村ごとの人口動態、課題、助成制度などのデータを提供しており、地域活性化に取り組む事業者の方などにとっては、有用なデータが見つかるかと思います。
更に、シェアリングエコノミーの雄Airbnbのデータが『Inside Airbnb』というサイトで公開されており、物件地域、宿泊費、レビュー数などのデータを使用することができます(今回はこちらのデータを使用します)。こちらは一般の有志により公開されているものです。
はじめに:回帰分析とは
今回はデータ分析の基本である「回帰分析」について、ご紹介いたします。
まず、回帰分析とは何か?端的に言うと、「ある変数(x)からもう一つ別の変数の値(y)を予測する手法」または、「変数の値(y)に影響する変数(x)を明らかにする手法」です。(ここでは、xのことを説明変数、yのことを目的変数と呼びます。)
簡単な例を挙げると:
「コンビニエンスストアで売られているチョコレートの値段から一日の売上数を予測することはできるか?」
ここで、チョコレートの値段はx、売上数をyとし、とあるコンビニエンスストアのチョコの値段と売上のデータを基に、このような式が立てられるとします:
y = -20x + 100
これはつまり、「チョコの値段が1円上がると売上数が20個減少する」ということです。現実的な話ではありませんが、このようにして、変数どうしの関係性、すなわちデータの法則性を見出すことができます。xの数値からyを予測できることによって、様々なアクションを取ることができます。例えばここでは、売上数を値段から予測することで、最適な値段を考えることができます。
このように、変数の数が少ない場合(yに対してxが一つだけ)で二つの関係性が自明の場合もありますが、データが複雑になればなるほど目的変数と説明変数の関係性を見出すのは難しいため、回帰分析が強力なツールとなり得るわけです。
実践:Airbnbのオープンデータを使用し、宿泊費の予測モデルを構築
<導入>
これから、実存するデータを基に回帰分析を行い、何か興味深い考察ができるか見ていきたいと思います。今回は、米ニューヨーク市のAirbnbに関するデータを使います。具体的には、ニューヨーク市のAirbnbに登録されている宿泊施設の情報から宿泊にかかる費用を予測します。
(Airbnb:https://www.airbnb.jp/)
<データ>
『InsideAirbnb』で公開されている、ニューヨーク市のAirbnbに関するオープンデータを用います。特に今回注目するのは、ニューヨーク市内のすべてのAirbnb登録下の宿泊施設の以下の情報です。
- 地理的情報(所属する行政区)
- 宿泊施設のタイプ(アパート・家の全てか、個室か、シェアルームか)
- 一泊するための宿泊費
- 最低宿泊日数
- レビューの数、月平均数
- 一年で宿泊可能な日数
これらに加え、行政区の治安情報(2015年における犯罪の数)を追加しました。ここで含めた重罪は、殺人、窃盗、暴行、不法侵入、そして強盗です。
(InsideAirbnb:http://insideairbnb.com/)
(アメリカ政府オープンデータ/ニューヨーク市の犯罪統計:http://www1.nyc.gov/site/planning/data-maps/nyc-population/current-future-populations.page)
<方法>
回帰分析の手順は簡略化し、以下の通りです。
- 予測モデルを構築する
※実際の構築方法はいくつかありますが、ここでは簡略化のために省略します。
詳しくは、「ステップワイズ法」を参照してください。
- 変数の有意性やモデルのあてはまりの良さを見極める
- モデルが回帰分析の前提条件を満たすか検証する
- 必要に応じてデータを変換する
- 大まかに前提条件を満たすまで1‐3を繰り返す
この際目指すのは、なるべくシンプルな予測モデルを構築することです。複雑すぎるモデルを構築しても、モデルの意味が理解できなければ元も子もありません。また、完璧に前提条件を満たせるようなキレイなデータはそうそうありません。このように、統計分析は非常にグレーゾーンが多くなってしまいがちです。このようなグレーゾーンを上手く見極めながら、有用な情報を引き出すことが大切です。
<結果と考察>
上記の手順に基づいてモデルを構築すると、
◆モデル
log(price) = 4.16 + 0.81(home) + 0.30(manhattan)
◆変数
price:宿泊費
home:宿泊施設が家/アパート全部屋かどうか。全部屋の場合は1、それ以外(10部屋の内)は1部屋のみ借りるなど)は0
manhattan:宿泊施設がマンハッタンにあるかどうか(マンハッタンの場合は1、それ以外は0)
◆決定係数
R2(決定係数)は0.52、それぞれの説明変数は有意。
R2(決定係数)とは、目的変数の総変動のうち、説明変数によって説明できる割合であり、つまり「回帰モデルの当てはまりの良さ・精度」を示しています。
つまり、R2(決定係数)0.52というと、ニューヨーク市のAirbnbの宿泊施設の宿泊費の約半分は、その施設が「家・アパートをまるまる貸し切りかどうか」、そして「マンハッタンにあるかどうか」によって説明できる、ということです。
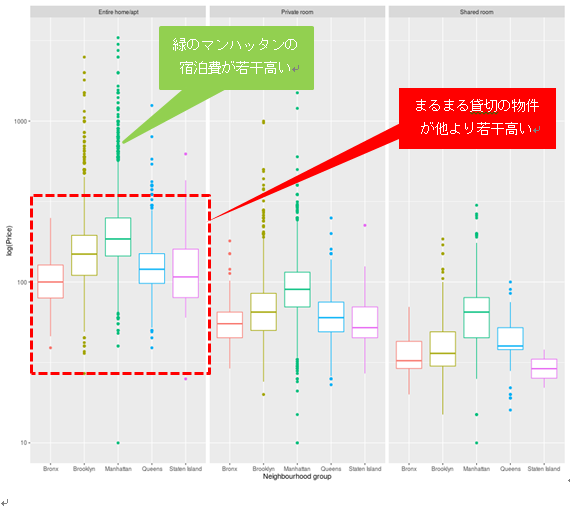
以上の結果、ある意味当然かと思います。マンハッタンは言わずと知れた世界経済や文化の中心地です。観光客も多く訪れるため、宿泊費が高いのもうなずけます。また家やアパートをまるまる借りるとなれば宿泊費は高くなります。逆に言えば、それ以外の変数はそれほど重要ではないわけです。治安の良し悪しやレビューの数なども、価格決定に大きな影響は及ぼさないということが分かりました。(レビューが多い人気の物件は高く、治安が悪い場所は安い、と予想していましたが…)
では、残りの半分は一体何でしょうか?私の推察は、
- 季節
- 物件の設備やアメニティ(洗濯機、Wi-fi、キッチンの有無など)
需要の多い夏休みや冬休みは価格が上がると考えるのが自然だと思います。ホストは自由に価格を上下できるため、季節によって価格を上げ下げするのは妥当です。また、大きなイベントなどがある際も上がるのではないでしょうか。さらに、設備が充実している方が高くなるのも自然だと思います。しかし、これらに関するデータは得られなかったため、推測の域を出ません。
まとめ
最後に今回のブログの内容をまとめます。
- 回帰分析はデータを予測し、考察するための基本的な手段
- 立地と物件の広さがニューヨーク市のAirbnb宿泊費の主な影響要因
- レビューの多さ、地域はAirbnb宿泊費には影響せず
出典
- Airbnb: https://www.airbnb.jp/
- InsideAirbnb: http://insideairbnb.com/index.html
- アメリカ政府オープンデータ/ニューヨーク市の犯罪統計:http://www1.nyc.gov/site/planning/data-maps/nyc-population/current-future-populations.page